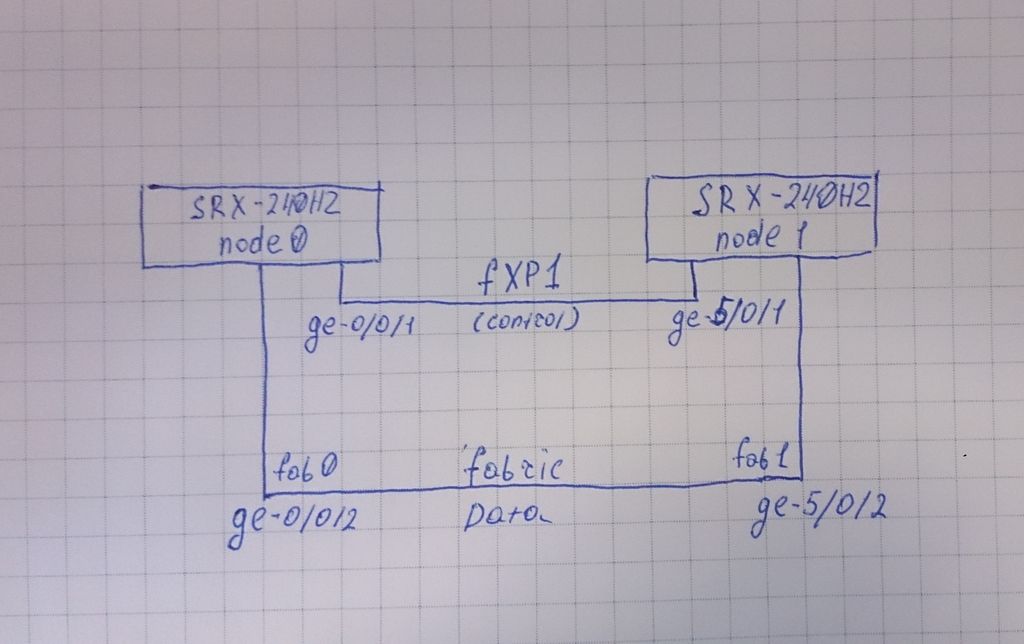
В целях повышения отказоустойчивости сети используется «горячий» резерв граничных устройств. У Juniper есть «штатная» возможность объединения в кластер. Итак перейдем непосредственно к делу: У нас имеется 2 устройства Juniper SRX240H2, стоит задача обеспечить горячий резерв. На SRX-240 интерфейсы: ge-0/0/0 — после объединения в кластер становятся интерфейсом fxp0, который в дальнейшем будет использоваться для управления устройствами. ge-0/0/1 — после объединения в кластер становятся интерфейсом fxp1, который используется как control link В качестве fabric интерфейса можно определить какой угодно, я взял следующий, соответственно ge-0/0/2. Заранее соединил устройства и подключился к обоим через консольный порт.

Итак устройства у нас подключены по такой схеме:
Перед тем как начать собирать кластер нужно убедиться что у нас нет ethernet switching(а) и VLAN(ов). На каждом устройстве выполняем команды:
[edit] root# delete interfaces ge-0/0/0 [edit] root# delete interfaces ge-0/0/1 [edit] root# delete interfaces ge-0/0/2 root# delete security zones security-zone untrust interfaces ge-0/0/0 [edit] root# commit and-quit
Таким образом удаляем описание, нужных нам для объединения в кластер, интерфейсов из конфигурации устройства. Если конфигурация не дефолтная, как в моем случае, возможно, данные интерфейсы описаны где то еще — это тоже нужно учесть. Теперь можно перейти непосредственно к кластеру: первым делом выполняем команды:
на первом устройстве:
srx>set chassis cluster cluster-id 1 node 0 reboot
на втором устройстве:
srx>set chassis cluster cluster-id 1 node 1 reboot
После перезагрузки можно изменять конфигурацию только на одном устройстве (ноде), конфигурация автоматически будет распространяться на весь кластер. В случае с SRX-240, интерфейсы второй ноды будут именоваться с цифры 5, подробнее об именовании интерфейсов можно почитать в базе знаний Juniper здесь или здесь, таким образом, например интерфейс который назывался ge-0/0/3 на устройстве, которое после объединения в кластер, стало node1, стал называться ge-5/0/3. Список доступных интерфейсов и их состояние можно посмотреть командой
{primary:node0}
root@srx> show interfaces terse
состояние кластера можно проверить командой
{primary:node1}
root@srx> show chassis cluster status
увидим что-то вроде этого:
Cluster ID: 1 Node Priority Status Preempt Manual failover Redundancy group: 0 , Failover count: 1 node0 1 primary no no node1 1 secondary no no
Далее дадим имена и настроим интерфейсы управления для каждой ноды, для этого на любом устройстве выполняем следующее:
{primary:node0}
root@srx> configure
warning: Clustering enabled; using private edit
warning: uncommitted changes will be discarded on exit
Entering configuration mode
{primary:node0}[edit]
root@srx#edit groups node0
{primary:node0}[edit groups node0]
root@SRX0# set system host-name SRX0
{primary:node0}[edit groups node0]
root@SRX0# set interfaces fxp0 unit 0 family inet address 10.10.1.1/24
{primary:node0}[edit groups node0]
root@SRX0# up 1 edit node1
{primary:node0}[edit groups node1]
root@SRX0# set system host-name SRX1
{primary:node0}[edit groups node1]
root@SRX0# set interfaces fxp0 unit 0 family inet address 10.10.1.2/24
{primary:node0}[edit groups node1]
root@SRX0# top
{primary:node0}[edit]
root@SRX0# set apply-groups ${node}
Переходим к настройке fabric интерфейсов, нам нужно указать в конфигурации имена интерфейсов, которые мы определили для использования в качестве fabric:
{primary:node0}[edit]
root# set interfaces fab0 fabric-options member-interfaces ge-0/0/2
{primary:node0}[edit]
root# set interfaces fab1 fabric-options member-interfaces ge-5/0/2
Первый этап настройки мы выполнили:
{primary:node0}[edit]
root@SRX0# commit
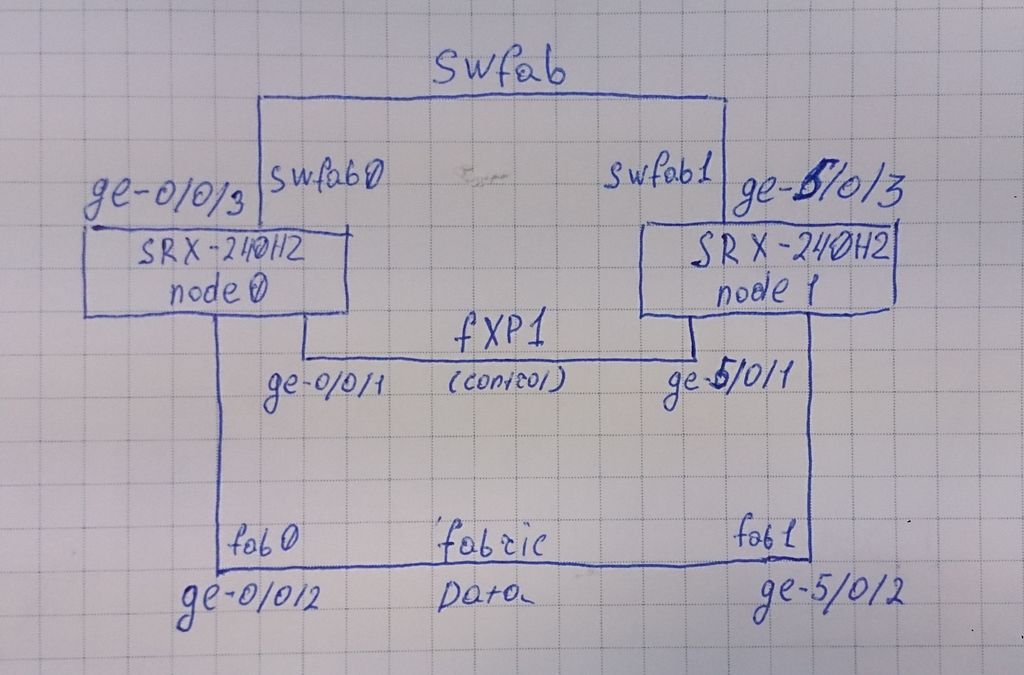
Если нужно обеспечить функцию свитчинга между устройствами кластера, то нам потребуется соединить их еще одним линком и назначить swfab интерфейсы. Я определил, что это будут ge-0/0/3 и ge-5/0/3. Схема подключения будет выглядеть следующим образом:

{primary:node0}[edit]
root@SRX0# set interfaces swfab0 fabric-options member-interfaces ge-0/0/3
{primary:node0}[edit]
root@SRX0# set interfaces swfab1 fabric-options member-interfaces ge-5/0/3
{primary:node0}[edit]
root@SRX0# commit
После этого, при настройке свитчинга, можно рассматривать интерфейсы разных нод, как интерфейсы одного физического устройства.
Теперь можно перейти к настройке redundancy-group. Это поможет нам объединить несколько физических интерфейсов в один виртуальный и назначить единый IP-адрес. В каждой группе избыточности (redundancy-group) будет первичное (primary) устройство и вторичное (secondary). В случае отказа первичного устройства вторичное берет на себя главенство в группе. На Juniper’ах, после того как собирается кластер, появляется redundancy-group 0 — эта группа избыточности регулирует отказоустойчивость routing engine каждой ноды. Т.е., с помощью redundancy-group 0 определяется, routing engine какой ноды будет использоваться. Нам остается только настроить приоритеты для каждой ноды:
{primary:node0}[edit]
root@SRX0# set chassis cluster redundancy-group 0 node 0 priority 100
{primary:node0}[edit]
root@SRX0# set chassis cluster redundancy-group 0 node 1 priority 99
Мы выставили ноде 0 приоритет выше чем ноде 1, таким образом при нормальных условиях у нас будет использоваться routing engine ноды 0, а в случае отказа ноды 0 главенство перейдет к ноде 1.
Теперь создадим redundancy-group для объединения интерфейсов в группы. Для балансировки можно использовать несколько таких групп избыточности, я для примера сделаю одну:
{primary:node0}[edit]
root@SRX0# set chassis cluster redundancy-group 1 node 0 priority 100
{primary:node0}[edit]
root@SRX0# set chassis cluster redundancy-group 1 node 1 priority 99
Я выставил приоритеты такие же, как у redundancy-group, можно было сделать и по-другому, например, дать ноде 1 приоритет выше чем у ноды 0: тогда при в обычном состоянии использовался физический интерфейс ноды 1, а в случае ее отказа будет задействована нода 0.
Если мы хотим, чтобы после восстановления после отказа главенство возвращалось в исходное положение, нам нужно выполнить следующую команду:
{primary:node0}[edit]
root@SRX0# set chassis cluster redundancy-group 1 preempt
Еще раз подчеркиваю, что это действие не обязательное, более того, эту команду лучше не выполнять, если хочется избежать еще одного обрыва связи, т.к. возврат в исходное состояние сопровождается потерями пакетов.
Перейдем к настройке виртуальных интерфейсов, которые будут служить для объединения физических интерфейсов группы. В начале нужно объявить максимальное количество таких интерфейсов. Мне в данном примере понадобится всего один, но в него я буду объединять интерфейсы ge-0/0/15 и ge-5/0/15 и хотел бы дать ему имя reth15. что бы в дальнейшем было легче читать конфигурационный файл. В связи с этим я скажу, что у меня таких интерфейсов 16. Если скажу что такой интерфейс один, Juniper позволит сконфигурировать только интерфейс reth0.
Не смотря на то, что интерфейсы не будут сконфигурированы, они создадутся и по этому, вывод команды show interface terse увеличится на количество созданных интерфейсов, но для меня это неудобство, которым можно пренебречь.
Итак:
{primary:node0}[edit]
root@SRX0# set chassis cluster reth-count 16
Дальше объединяем интерфейсы, для этого в настройках физических интерфейсов указываем, к какой группе они принадлежат:
{primary:node0}[edit]
root@SRX0# set interfaces ge-0/0/15 gigether-options redundant-parent reth15
{primary:node0}[edit]
root@SRX0# set interfaces ge-5/0/15 gigether-options redundant-parent reth15
Теперь конфигурация виртуального интерфейса. Здесь нужно определить, к какой группе избыточности (redundancy-group) он относится. Как я описывал выше, от этого будет зависеть, какой физический интерфейс будет задействован при обычных условиях, а какой будет резервным:
{primary:node0}[edit]
root@SRX0# set interfaces reth15 redundant-ether-options redundancy-group 1
схематично это выглядит вот так:

Далее настраиваем интерфейс reth15 так же как обычный интерфейс, например если нам нужно добавить IP адрес, то делаем следующим образом:
{primary:node0}[edit]
root@SRX0# set interfaces reth15 unit 0 family inet address 192.168.0.5/24
и т.д.
При текущей настройке система будет переходить на резервную ноду при отказе всей первичной ноды, но если пропадет линк только на одном интерфейсе, никакого перехода не произойдет, а если этот интерфейс является, например, аплинком, то мы потеряем связь. Чтобы избежать такого сценария, нам, помимо всего прочего, нужно мониторить интерфейсы, при отказе которых должен совершаться переход на резервную ноду. Для этого вернемся к настройке redundancy-group:
{primary:node0}[edit]
root@SRX0# set chassis cluster redundancy-group 1 interface-monitor ge-0/0/15
{primary:node0}[edit]
root@SRX0# commit
теперь при пропадании линка на интерфейсе ge-0/0/15, нода 1 возьмет на себя главенство в группе, и если есть настройка preempt, отдаст его обратно ноде 0 при появлении линка.
Кластер настроен ![]() , теперь можно переходить к индивидуальной настройке, в зависимости от задач.
, теперь можно переходить к индивидуальной настройке, в зависимости от задач.
первым делом выполняем на обоих устройствах команду
srx>set chassis cluster cluster-id 1 node 0 reboot
а на втором разве не
set chassis cluster cluster-id 1 node 1 reboot ?
Спасибо, поправил в тексте, чтобы стало очевидней
Офигенная статейка, настраивал кластер на многих моделях SRX, по статьям на оф. сайте джунипера, было сложно понять что для чего нужно, а здесь по-русски комментарии к каждому действию. Тем кто только сейчас начинает изучать джунипер и в поиске найдет эту статью будет намного проще понять что к чему)
Огромное человеческое спасибо автору….
Лучше вот тут про именование интерфейсов читать:
http://www.juniper.net/techpubs/en_US/junos15.1×49/topics/reference/general/chassis-cluster-srx-series-node-interface-understanding.html
Спасибо, добавил в статью.
Есть ошибка:
{primary:node0}[edit]
root@SRX0# set apply-groups node0
{primary:node0}[edit]
root@SRX0# set apply-groups node1
— вот эти 2 команды привели у меня к проблемам в кластере. В частности, ssh постоянно рвался… Фактически, каждая нода применяет эту команду сначала к одной ноде, а потом к другой. А должны каждая применять это только сама к себе. Вместо этих двух команд нужно выполнять одну:
set apply-groups «${node}»
— где переменная принимает значения node0 и node1 в зависимости от того, где выполняется. Инфа из курса Junos Security.
Здравствуйте, на текущий момент имеется в работе 3 кластера из SRXов, все настраивал именно так, пока не было эффекта, о котором вы говорите. Может быть это зависит от версии JunOS или от модели самого SRX, если не ошибаюсь, в курсе JunOS security говорилось о том, что настройка кластера на hi-end устройствах немного отличается. Моя инструкция испытывалась на SRX550 и SRX240. Обязательно приму к сведению Вашу рекомендацию и на досуге полистаю учебник по JSEC.
У меня SRX650, но рекомендация в JSEC (Chapter 11-16) дана безотносительно к версии SRX.
Ну и, чтобы 2 раза не вставать, добавлю: команда «set chassis cluster reth-count 16» не «позволяет создать до 16 интерфейсов reth», а сразу создаёт все эти 16 интерфейсов. Сразу после её выполнения (ну и commit, разумеется) вывод команды show interface terse становится длиннее на соответствующее число интерфейсов reth, пусть и не настроенных
Спасибо, внес обе Ваши поправки в свою статью.
Добрый день. Подскажите если у меня есть бэкап конфигурации 0 ноды кластера juniper
1. Нужно ли бэкапить 1 ноду?
2. Если требуется накатить бэкеап на кластер. Нужно сначала собрать кластер вручную а потом бэкапить?
Спасибо за ответ